Our new Git Branching Model
Creating meaningful branches in Git to support you in your workflow is hard. We used git-flow for the last years but finally decided it would be time to switch to another branching model.


One of the first concepts around Git, that most developers will get into contact with, is branching. And while branching is something that can certainly amplify your productivity and improve collaboration within the team, it's hard to get it right. That is where so-called „branching models“ come into play.
About Branching Models
A branching model or development model describes a strategy that is used by the team, that is responsible for a specific project, to organize the branches within a VCS (Version Control System) like Git. It's not just about which branches to create or about their names, but instead about the way developers interact with the project and its development. The branching model sets how branches are merged, how releases are created and which branches are protected (passive), and which branches are used for active development.
Every project with more than one contributor (and in my opinion even one-man-projects) should employ branching models, as they offer orientation and processes that can be followed, which is especially useful for new developers. A branching model ensures that everyone on the team is following the same procedures while making changes to the source control and therefore avoids mistakes.
Good branching models support the developers in their workflow. They do not force archaic rules upon them but instead, provide them with a technical foundation and are adjusted towards the way they work with each other. And because there are as many different workflows, as there are teams, branching models can and should be tailored towards those teams.
If you're interested, you can read more about branching models at the LaunchDarkly Blog. There are lots of things to know and they've done an excellent job at describing all the aspects to consider. I've tried to keep it short because this post is more about our journey than about the concept of branching models as a whole.
Our initial Branching Model
When we started using Git back in 2012, we searched for something stable and well-documented because we already had a hard time getting our heads around Git and its many features and concepts. So creating our own branching model was out of the question. Something, that caught our attention, was git-flow by Vincent Driessen.
There was a blog post on his homepage that explained all the moving parts visually and with examples for frequent use-cases as well as scripts for the individual steps. Those resources were a great aid in setting up our initial branching model. However, we made some small variations to the originally suggested model so that it matched better with our workflow.


Our branching model consisted of five types of different branches and each has its own, distinct purpose:
- master: The primary branch, that always represents the most recent, deployed stable code. Ideally, this branch would therefore always host the code of the most recent release branch and would be super stable. You can imagine it beings something like a manually tested
developmentbranch. - development: The stable branch for active development. All features and bug fixes are merged into this branch. They are aggregated here, tested, and then promoted to the
masterbranch as part of areleasebranch. - dev/name-of-feature: A single feature/bugfix branch that is (most often) managed by one developer. Those branches contain new (untested) changes and are merged through Pull Requests into the
developmentbranch after the changes have been reviewed and tested. - hotfix/1.0.0-name-of-fix: A single hotfix branch that contains a bugfix that is (in this case) based on version 1.0.0. Hotfix branches are only created for important bug fixes that cannot be delayed until the next release.
- release/1.0.0: A single release branch that is based on the
developmentbranch at a specific commit and is used for the deployment of (in this case) version 1.0.0. This is the code that runs on the server for a specific version.
Compared to the original git-flow branching model, we only renamed develop to development and the feature/ branches to dev/ branches and switched to the slash syntax, so that they are nicely grouped. We also made the Pull Requests mandatory to get from a dev/ branch to the development branch, but aside from that, we stayed pretty close to the original git-flow model.

dev/, hotfix/ and release/ branches are examples, as those types of branches can exist multiple times. It can be easily seen that the development branch and the individual dev/ branches are the heart of this branching model and will be created and used significantly more often than all other branch types.
Why it did not work for us
While this branching model somewhat "worked" for us, it also put some strain on our day-to-day work and over time it became apparent, that some parts of git-flow do not align with how we think about software and how we manage releases and features.
There were two aspects that we struggled with the most: Releases and the master branch. We only develop in-house software – programs, that will only be executed within our organization and within the context of our organization. Therefore, release branches serve really little purpose for us, while on the other hand, creating much work for our developers.
Whenever a new release needed to be created, a proper release/ branch needed to be created, the version needed to be bumped within that branch, then a git tag was created, and the release/ branch was merged back into master and development and the version is bumped again within the development branch. Without proper tooling, this process could take something between 10 minutes and 30 minutes and there was much space for errors.
Then we would always be left with a release/ branch, that we would never touch anyway, as we only support the newest version since we are the only "customer" and the branches were even redundant for historical purposes, as we already created the tags, so we could easily revisit specific releases without the branches.
On top of that, we create (more or less) rolling releases (aside from major feature updates). Features are deployed whenever they are ready and tested and so we never think of software in terms of specific releases. And that is why we never really used the master branch. Sometimes the last commit to the master branch was 8 months ago, while there were plenty of commits to the other branches every day.
Not using the master branch comes with its own set of disadvantages:
- We could not automatically close issues with commits, as they would only be closed by commits to the master branch.
- Sentry could not properly track our released versions as it would always monitor the
masterbranch and see no changes. - Every time a developer wanted to quickly jump into the code of a project, he needed to switch to the
developmentbranch first. - When checking out new projects, the
masterbranch is selected by default and those old dependencies will be downloaded, before the developer switches to the correct branch. - Pull Requests in the Gitlab UI are targeted against the
masterbranch by default, leading to many wrong Pull Requests (especially from new developers).
And we never updated master, as that was just so much effort, that it never "felt worth it" for those small changes. It felt kinda arbitrary to create a release for any commit, as there were bigger commits in the past, that we had not created releases for.
In the meantime, even Vincent Driessen (nvie) himself revisited his original blog post and stated, that it may not be the best fit for modern software development for very similar reasons:
This model was conceived in 2010, now more than 10 years ago, and not very long after Git itself came into being. In those 10 years, git-flow (the branching model laid out in this article) has become hugely popular in many a software team to the point where people have started treating it like a standard of sorts — but unfortunately also as a dogma or panacea.
During those 10 years, Git itself has taken the world by a storm, and the most popular type of software that is being developed with Git is shifting more towards web apps — at least in my filter bubble. Web apps are typically continuously delivered, not rolled back, and you don't have to support multiple versions of the software running in the wild.
This is not the class of software that I had in mind when I wrote the blog post 10 years ago. If your team is doing continuous delivery of software, I would suggest to adopt a much simpler workflow (like GitHub flow) instead of trying to shoehorn git-flow into your team.
If, however, you are building software that is explicitly versioned, or if you need to support multiple versions of your software in the wild, then git-flow may still be as good of a fit to your team as it has been to people in the last 10 years. In that case, please read on.
To conclude, always remember that panaceas don't exist. Consider your own context. Don't be hating. Decide for yourself.
With all those problems in mind, we intended to remove a lot of the complexity and bureaucracy and wanted to strip the system down to its bare minimum that supports us in our day-to-day business.
What we ended up with
On the 8th of July 2021, I suggested a more streamlined and simple approach for our Git branching model. By cutting away everything that served little to no purpose for our development model, and focusing on the parts that we use in our daily workflow, we can focus less on how we manage our code and more on the code itself.
To outline the differences between our new model and the old one, I'm gonna explain our new model first:
- main: The new primary branch. It is a combination of the old
masteranddevelopmentbranches but based only on the commits of the latter. There is only one branch now and it is stable. In this branch, all changes are aggregated before they are deployed. Real releases are no longer created in their own branch but instead are represented exclusively by Git tags on this branch. We don't need the branches, as we will never base our work on specific released versions (besides hotfixes) but the current state of the main branch instead. The tags are named likev1.0.0. - dev/name-of-feature: This type of branch is retained, but now derives from the
mainbranch and is also merged back into this branch. That simplifies the process of merging in changes significantly, prevents careless mistakes, and fits the perception of releases and the current state of development better. Features are considered finished, as soon as they are merged into themainbranch. The previous scenario, where we had to wait on the merge to master does not match how development feels or should feel. - hotfix/1.0.0-name-of-fix: This type of branch is retained as well, but now derives from the version tag and not from the (now no longer existing)
release/branches. That works equally as well but is now only visible whenever a hotfix is necessary. That's certainly not the case for every release and therefore thehotfix/branches stay invisible most of the time. After the next release is created, which fixes this bug, thehotfix/branch is deleted, because it has no historic relevance. We don't backport any changes and always only support the newest version, so hotfixes can be ignored then.
That way, we only have the main branch and some dev/ branches (where the active development happens) most of the time. With that branching model, we can utilize more Gitlab comfort features and are more agile with our releases. We also have a better understanding and overview of our development in general. It's easier for new developers to understand the model, we save space and we probably make fewer careless mistakes (because the processes are easier and consist of fewer individual steps).

We decided to name it main and not name it master or development (even though the code was completely copied from development) to prevent confusion and to align our repositories with the recommendations for less discriminatory language.
After my suggestion was accepted by our developers and we made sure that we are covering all existing use-cases, we planned the great switch across all projects (43 at the time). We wanted to cause as little disruption as possible, so we fully migrated one project after another and only migrated the projects once there were no open Pull Requests.
The migration happened over three days and was finished on the 12th of July 2021. We needed to change the branches themselves, modify the pipeline definitions, default branches, and our local checked-out copies of the repositories.
Our Git Workflow for Features
Now that we've switched to our new branching model, it might be worth outlining how we interact with the model when adding new features or fixing bugs in the existing codebase. Releases are as simple as creating a new Git tag, so there's little benefit in explaining how we perform them.
First, a corresponding issue is created within GitLab. Technically, issues are outside of Git's scope (or the scope of the branching model), but since there is almost every time an issue is created before we start working on it, this step had to be included in our workflow as well.
- A new dev branch (
dev/feature-name) is created from themainbranch - The necessary changes are committed to the newly created branch
- A Pull Request to merge this branch back into
mainis opened within GitLab - The Pull Request is peer-reviewed by at least one other team member and all pipelines must succeed
- The corresponding dev branch is rebased onto the
mainbranch - All changes on the dev branch are squashed into one single commit with a meaningful description of the feature, the motivation, and the change itself
- The dev branch is merged into the
mainbranch in fast-forward mode, so that no merge commit is appended - The dev branch is deleted
All those steps are executed either directly with the Git CLI/IntelliJ IDEA or through the GitLab web interface.
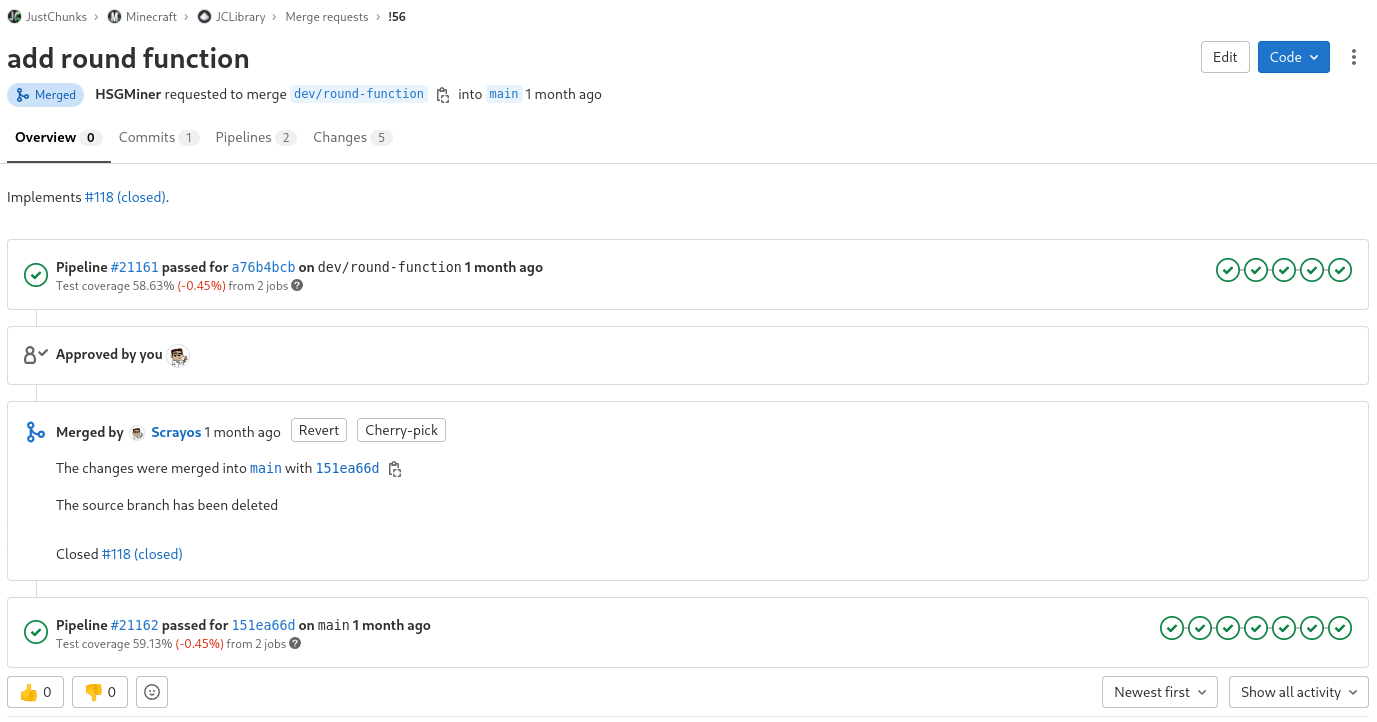
This workflow allows us to track semantic changes in our codebase and provides us with meaningful insights into the evolution of our codebase. The peer review not only improves the quality of our code but also prevents us from ever playing the "blame game", because there is never a single person responsible for some bug, because at least one other person also didn't see the problem in advance.
Lessons Learned
Git branching models are not set in stone. They are changing, evolving, and adapting – just like the developers that use them and the software that is managed through them. This may not be the last time that we alter our branching model, but it certainly was worth the effort.
One aspect that became very clear while investigating our options was that we can avoid much complexity because we are a small team and we maintain great communication between our team members. Bigger or even more distributed teams may need to set up more policies and therefore need more complex branching models and processes.
We are very happy with the new branching model, but if there are new requirements in the future that we cannot solve with what we have now, we will revisit the branching model.
Did you like this Post?
If you (ideally) speak German and are interested in working in a friendly environment with lots of interesting technologies, experimentation, and passionate other people, feel free to reach out to us! We're always looking for new team members. For contact information and an overview of our project, the skills you need to possess, and the problems you'll be facing, head to our job posting!
We're constantly working on exciting stuff like this and would love you to take part in the development of JustChunks. If you're just interested in more JustChunks related development or want to get in touch with the community, feel free to read our weekly, german recaps here or hop on our discord server!
